Chinese AI researchers have achieved what many thought light years had been removed: a free, open-source AI model that can match or even surpass the performance of the most advanced reasoning systems. What makes this even more remarkable is the way they did it: by letting the AI learn themselves by trial and error, similar to how people learn.
“Deepseek-R1-Zero, a model that has been trained through large-scale reinforcement learning (RL) without guided fine tuning (SFT) as a preparatory step, demonstrates remarkable reasoning options.” is the research paper.
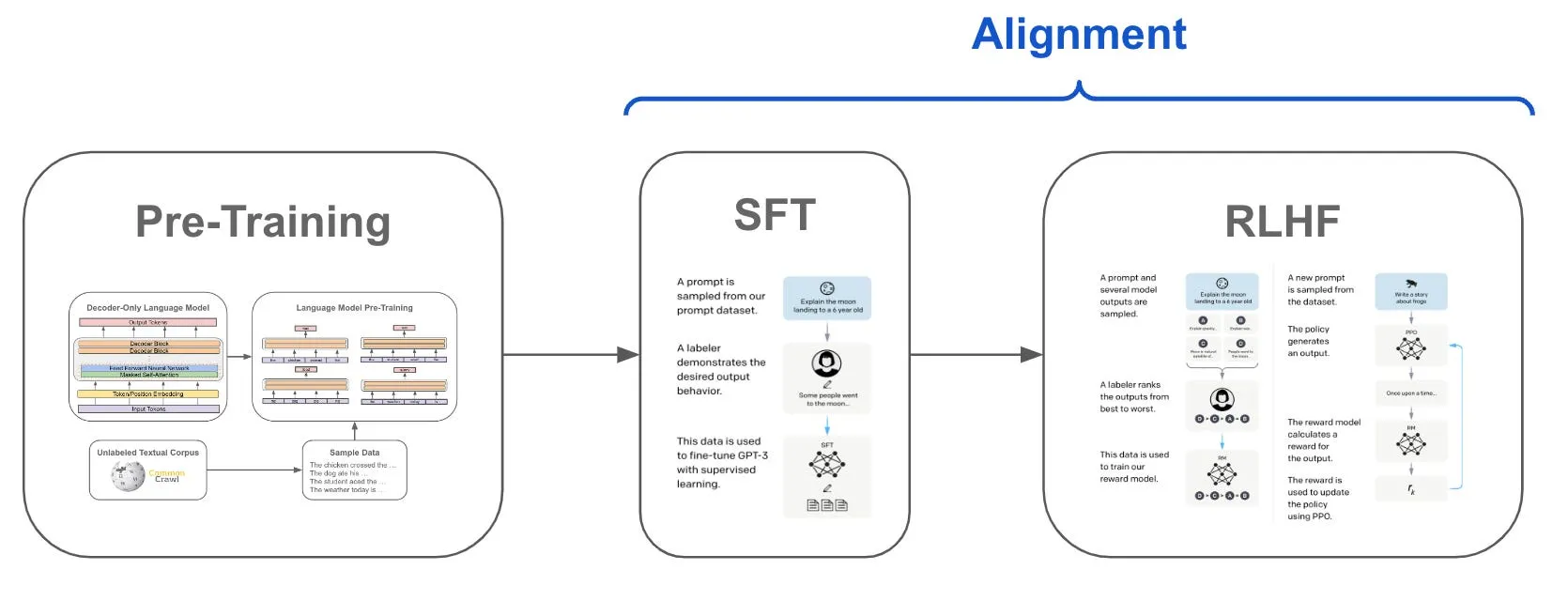
‘Reinforcement Learning’ is a method in which a model is rewarded for making good decisions and is punished for making bad decisions, without knowing which one is. After a series of decisions, it learns to follow a path that is strengthened by those results.
In the first instance, during the controlled refinement phase, a group of people tell the model which desired output they want, which gives it context to know what is good and what is not. This leads to the next phase, Reinforcement Learning, in which a model yields different results and people rank the best. The process is repeated time and time again until the model knows how to consistently produce satisfactory results.
Image: Deepseek
Deepseek R1 is a guideline for the development of AI, because people play a minimal role in training. Unlike other models that have been trained on large amounts of monitored data, Deepseek R1 mainly learns through mechanically reinforcing learning – in essence by sorting things out by experimenting and getting feedback about what works.
“Via RL, Deepseek-R1-Zero naturally emerges with numerous powerful and interesting reasoning behavior,” the researchers said in their article. The model even developed advanced possibilities such as self -verification and reflection without it being explicitly programmed.
As the model went through its training process, it naturally learned to allocate more ‘thinking time’ to complex problems and developed the ability to recognize his own mistakes. The researchers emphasized one “A-HA Moment” Where the model learned to re -evaluate his initial approach to problems – something for which it was not explicitly programmed.
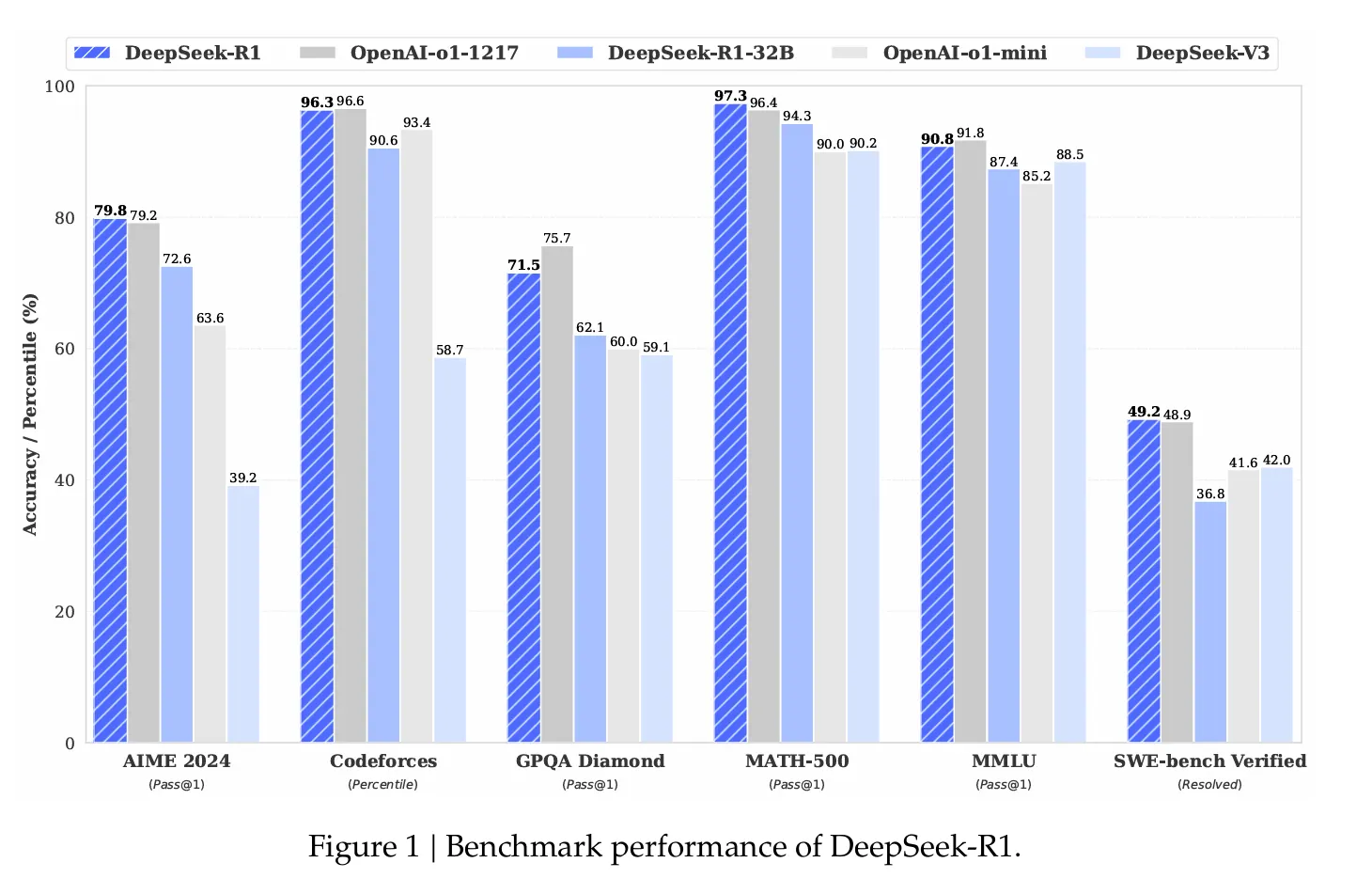
The performance figures are impressive. On the AIM 2024-Wiemiekebenchmark, Deepseek R1 achieved a success rate of 79.8%, with which it surpassed the O1 reasoning model of OpenAi. In the case of standardized coder tests, the performance at “expert level” demonstrated, achieved an ELO assessment of 2,029 on code forces and performed better than 96.3% of human competitors.
Image: Deepseek
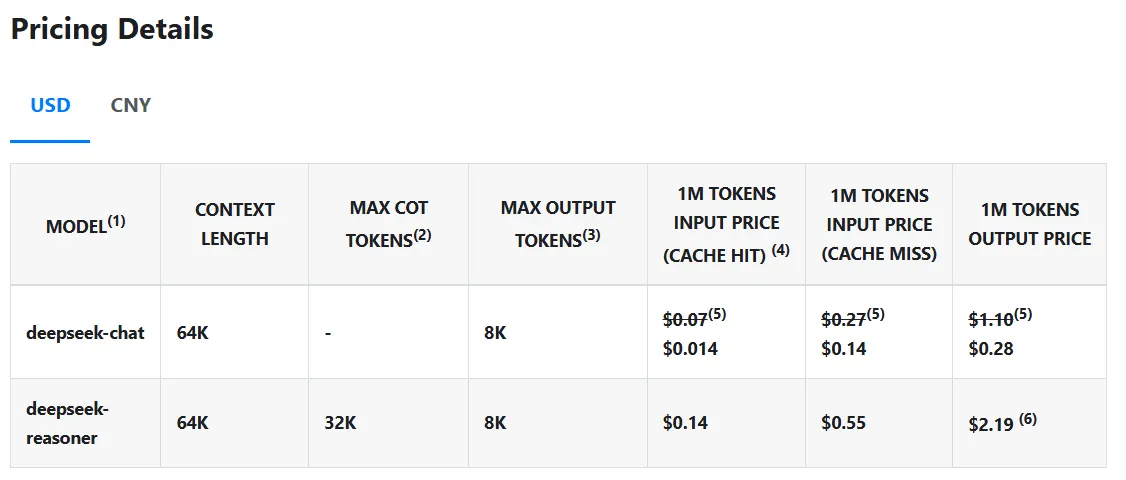
But what Deepseek R1 really distinguishes are the costs – or the lack thereof. The model performs queries for only $ 0.14 per million tokens, compared to OpenAI’s $ 7.50, making it 98% cheaper. And unlike proprietary models, the code and training methods of Deepseek R1 are fully open source under the MIT license, which means that everyone can grab the model, use it and adjust without limitations.
The release of Deepseek R1 has triggered an avalanche of reactions from leaders from the AI industry, whereby many emphasize the importance of a fully open sourcem model that corresponds to their own leaders in terms of reasoning.
Nvidia’s top researcher Dr. Jim Fan perhaps delivered the most sharp comment and pulled a direct parallel with the original mission of OpenAi. “We live in a timeline in which a non -American company keeps the original mission of OpenAi alive – really open border research that everyone empowered”, Fan noted, praising the unprecedented transparency of Deepseek.
We live in a timeline in which a non-American company keeps the original mission of OpenAi alive: really open, groundbreaking research that empowered everyone. It makes no sense. The most entertaining outcome is the most likely.
Fan called the importance of the reinforcing learning approach of Deepseek: “They are perhaps the first [open source software] project that shows great sustainable growth of [a reinforcement learning] flywheel. He also praised the uncomplicated parts through the Deepseek of ‘raw algorithms and matplotlib-learning’ versus the hype-driven announcements that occur more often in the industry.
Apple researcher Awni Hannun said that people can run a quantized version of the model locally on their Mac.
Deepseek R1 671B runs on 2 m2 ultras faster than reading speed.
Close to open-source O1, at home, on consumer hardware.
Traditionally, Apple devices were weak in the field of AI because of their lack of compatibility with Nvidia’s Cuda software, but that seems to change. AI researcher Alex Cheema, for example, was able to use the entire model after he used the power of eight Apple Mac Mini units that worked together. That is still cheaper than the servers needed to run the most powerful AI models that are currently available.
That said, users can run lighter versions of Deepseek R1 on their Macs with a good level of accuracy and efficiency.
However, the most interesting reactions came after we had wondered how close the open source industry is in the proprietary models, and what potential impact this development can have for OpenAI as a leader in the field of reasoning AI models.
Stability AI founder Emad Mostaque took a provocative position and suggested that the release is pressure on better funded competitors: “You can imagine that you are a border laboratory that has collected about a billion dollars and now you cannot do your latest model release because it can’t beat Deepseek? “
Can you imagine that you are a border laboratory that has collected around a billion dollars and cannot release your newest model because it is not up to Deepseek? 🐳
Based on the same reasoning, but with a more serious argumentation, Tech entrepreneur Arnaud Bertrand explained that the rise of a competitive open source model can potentially be harmful to OpenAI, because that makes its models less attractive to powerusers who would otherwise be prepared otherwise To spend a few euros. A lot of money per task.
CEO of Perplexity AI, Arvind Srinivas, formulated the release in terms of the impact on the market: “Deepseek has largely replicated O1 mini and made the open source.” In a follow -up observation, he noticed the rapid pace of progress: “It is quite wild to see that reasoning becomes a standard so quickly.”
It is quite wild to see that reasoning becomes a commodity so quickly. Towards the end of the year, probably even halfway through the year, we can expect a model at O3 level that open source is. pic.twitter.com/oyixks4udm
Srinivas said that his team will work on it to bring the reasoning options of Deepsek R1 to Perplexity Pro in the future.
Fast hands-on
We have done a few quick tests to compare the model with OpenAI O1, starting with a well -known question for this kind of benchmarks: “How many Rs are there in the word strawberry?”
Models usually have difficulty giving the correct answer because they do not work with words; They work with tokens, digital representations of concepts.
GPT-4O failed, OpenAI O1 succeeded-and that also applied to Deepseek R1.
However, O1 was very concise in the reasoning process, while Deepseek applied a serious reasoning output. Interestingly enough, Deepseek’s answer felt more human. During the reasoning process, the model seemed to talk to himself, using jargon and words that are unusual on machines, but are used by people on a larger scale.
For example, while the model thought about the number of RS, it said to itself, “Okay, let me figure this out.” It also used ‘hmmm’ during debating, and even said things like ‘waiting, no. Wait, let’s split it.
The model ultimately achieved the right results, but spent a lot of time on reasoning and spitting tokens. Under normal price conditions this would be a disadvantage; But given the current state of affairs, it can produce much more tokens than OpenAI O1 and yet be competitive.
Another test to see how well the models could reason was to play ‘spies’ and identify the perpetrators in a short story. We choose an example from the Big-Bench dataset on Github. (The full story is available here and is about a school trip to a remote, snowy location, where students and teachers are confronted with a series of strange disappearances and the model must find out who the stalker was.)
Both models thought about it for more than a minute. However, Chatgpt crashed before the mystery was resolved:
But Deepseek gave the correct answer after he had thought about it for 106 seconds. The thinking process was correct and the model was even able to correct itself after it had come to incorrect (but still logically enough) conclusions.
The accessibility of smaller versions in particular impressed researchers. To context: a model of 1.5 billion is so small that you could use it locally on a powerful smartphone in theory. And even such a small quantized version of Deepseek R1 was able to compete against GPT-4O and Claude 3.5 Sonnet, according to data scientist Vaibhav Srivastav from Hugging Face.
“Deepseek-R1-Distill-Qwen-1.5b performs better than GPT-4O and Claude-3.5 Sonnet on mathematical benchmarks with 28.9% on aime and 83.9% on Math.”
Just a week ago, Skynove from UC Berkeley Sky T1 released, a reasoning model that can also compete with OpenAI O1 Preview.
Those who are interested in carrying out the model locally can download Github or Huggingf Face. Users can download, implement, remove censorship or adjust it to different areas of expertise by refining it.
Or if you want to try the model online, go to Hugging Chat or Deepseek’s web portal, which is a good alternative to chatgpt, especially because it is free, open source and the only AI-chatbot interface with a model that is built next to chatgpt to reason.
Edited by Andrew Hayward
Generally intelligent Newsletter
A weekly AI trip told by Gen, a generative AI model.