
De in San Francisco gevestigde antropische antropische daalde zojuist de vierde generatie van zijn Claude AI-modellen, en de resultaten zijn … ingewikkeld. Terwijl Google context Windows voorbij een miljoen tokens duwt en OpenAI multimodale systemen bouwt die antropisch zien, horen en spreken, is antropisch vastgehouden met dezelfde 200.000-topping limiet en alleen-tekstbenadering. Het is nu de vreemde onder grote AI -bedrijven.
De timing voelt opzettelijk aan – Google heeft deze week ook Gemini aangekondigd en Openai onthulde een nieuwe coderingsagent op basis van zijn eigen Codex -model. Claude’s antwoord? Hybride modellen die verschuiven tussen redeneren en niet-herhalende modi, afhankelijk van wat je naar hen gooit-verstrekken wat Openai verwacht te brengen wanneer ze GPT-5 vrijgeven.
Maar hier is iets voor API -gebruikers om serieus te overwegen: Anthropic brengt premium prijzen in rekening voor die upgrade.
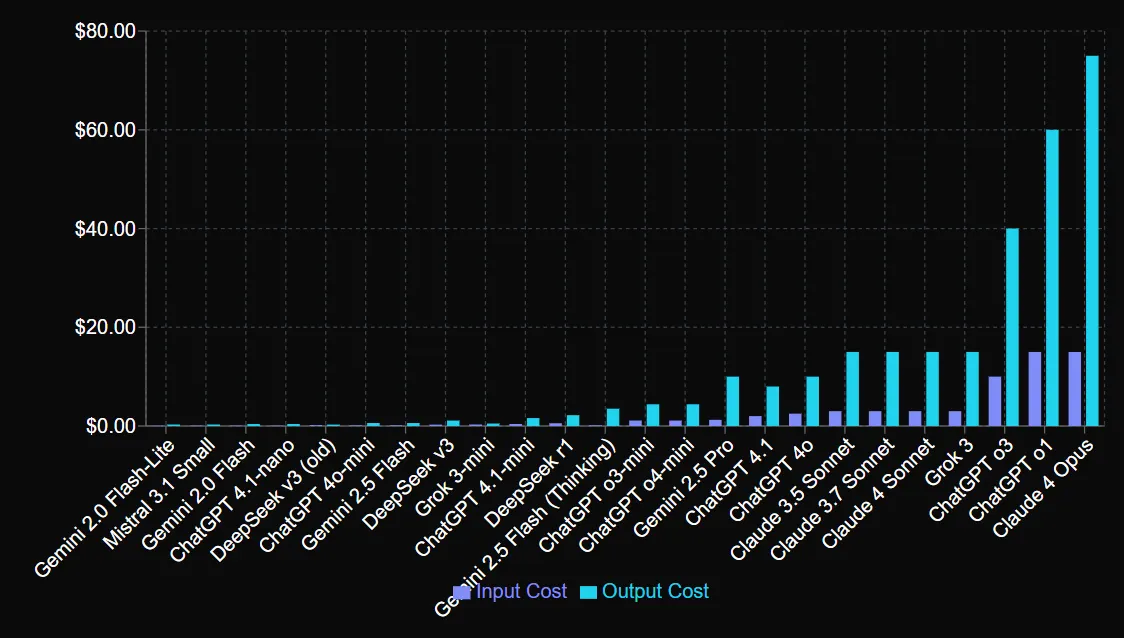
De chatbot -app blijft echter hetzelfde op $ 20 met Claude Max geprijsd op $ 200 per maand, met 20x hogere gebruikslimieten.
We hebben de nieuwe modellen op de stappen gezet over creatief schrijven, coderen, wiskunde en redeneringstaken. De resultaten vertellen een interessant verhaal met marginale verbeteringen op sommige gebieden, verrassende verbetering in andere en een duidelijke verschuiving in de prioriteiten van Anthropic weg van algemeen gebruik naar ontwikkelaarsgerichte functies.
Hier is hoe zowel Claude Sonnet 4 als Claude Opus 4 in onze verschillende tests presteerden. (U kunt ze bekijken, inclusief onze prompts en resultaten, in onze GitHub -repository.)
Creatief schrijven
Creatieve schrijfmogelijkheden bepalen of AI -modellen boeiende verhalen kunnen produceren, consistente toon kunnen behouden en feitelijke elementen op natuurlijke wijze kunnen integreren. Deze vaardigheden zijn belangrijk voor makers van inhoud, marketeers en iedereen die AI -hulp nodig heeft bij het vertellen van verhalen of overtuigend schrijven.
Vanaf nu is er geen model dat Claude kan verslaan in deze subjectieve test (natuurlijk niet overwegen Longwriter). Het heeft dus geen zin om Claude te vergelijken met opties van derden. Voor deze taak hebben we besloten om Sonnet en Opus face-to-face te plaatsen.
We vroegen de modellen om een kort verhaal te schrijven over een persoon die terug in de tijd reist om een catastrofe te voorkomen, maar zich uiteindelijk realiseerde dat hun acties uit het verleden eigenlijk deel uitmaakten van de gebeurtenissen die het bestaan maakten naar die specifieke toekomst. De prompt heeft enkele details toegevoegd om te overwegen en gaf modellen voldoende vrijheid en creativiteit om een verhaal op te zetten als ze dat nodig achten.
Claude Sonnet 4 produceerde levendig proza met de beste atmosferische details en psychologische nuance. Het model vervaardigde meeslepende beschrijvingen en gaf een boeiend verhaal, hoewel het einde niet precies was zoals gevraagd – maar het paste bij het verhaal en het verwachte resultaat.
Over het algemeen evenwichtige constructie van Sonnet, evenwichtige actie, introspectie en filosofische inzichten over historische onvermijdelijkheid.
Score: 9/10– Definig beter dan Claude 3.7 Sonnet
Claude Opus 4 heeft zijn speculatieve fictie gebaseerd in geloofwaardige historische contexten, verwijzend naar inheemse wereldbeelden en pre-koloniale Tupi Society met zorgvuldige aandacht voor culturele beperkingen. Het model geïntegreerde bronmateriaal op natuurlijke wijze en bood een langer verhaal dan sonnet, zonder helaas de poëtische flair te kunnen matchen.
Het toonde ook iets interessants: het verhaal begon veel levendiger en was meeslepender dan wat Sonnet bood, maar ergens rond het midden verschoof het om de plotwending te haasten, waardoor het hele resultaat saai en voorspelbaar was.
Score: 8/10
Sonnet 4 is de winnaar voor creatief schrijven, hoewel de marge smal bleef. Schrijvers, pas op: in tegenstelling tot eerdere modellen, lijkt het erop dat antropisch geen prioriteit heeft gegeven aan creatieve schrijfverbeteringen, waardoor ontwikkelingsinspanningen elders worden gericht.
Alle verhalen zijn hier beschikbaar.
Codering
Codering evaluatiemaatregelen of AI functionele, onderhoudbare software kan genereren die de best practices volgt. Deze mogelijkheid treft ontwikkelaars die AI gebruiken voor het genereren van codes, foutopsporing en architecturale beslissingen.
Gemini 2.5 Pro wordt beschouwd als de koning van AI-aangedreven codering, dus hebben we het getest tegen Claude Opus 4 met langdurig denken.
We schieten onze instructies voor een spel op, een robot die journalisten op zijn manier moet vermijden om met een computer te fuseren en AGI te bereiken-en gebruikten een extra iteratie om bugs te repareren en verschillende aspecten van het spel te verduidelijken.
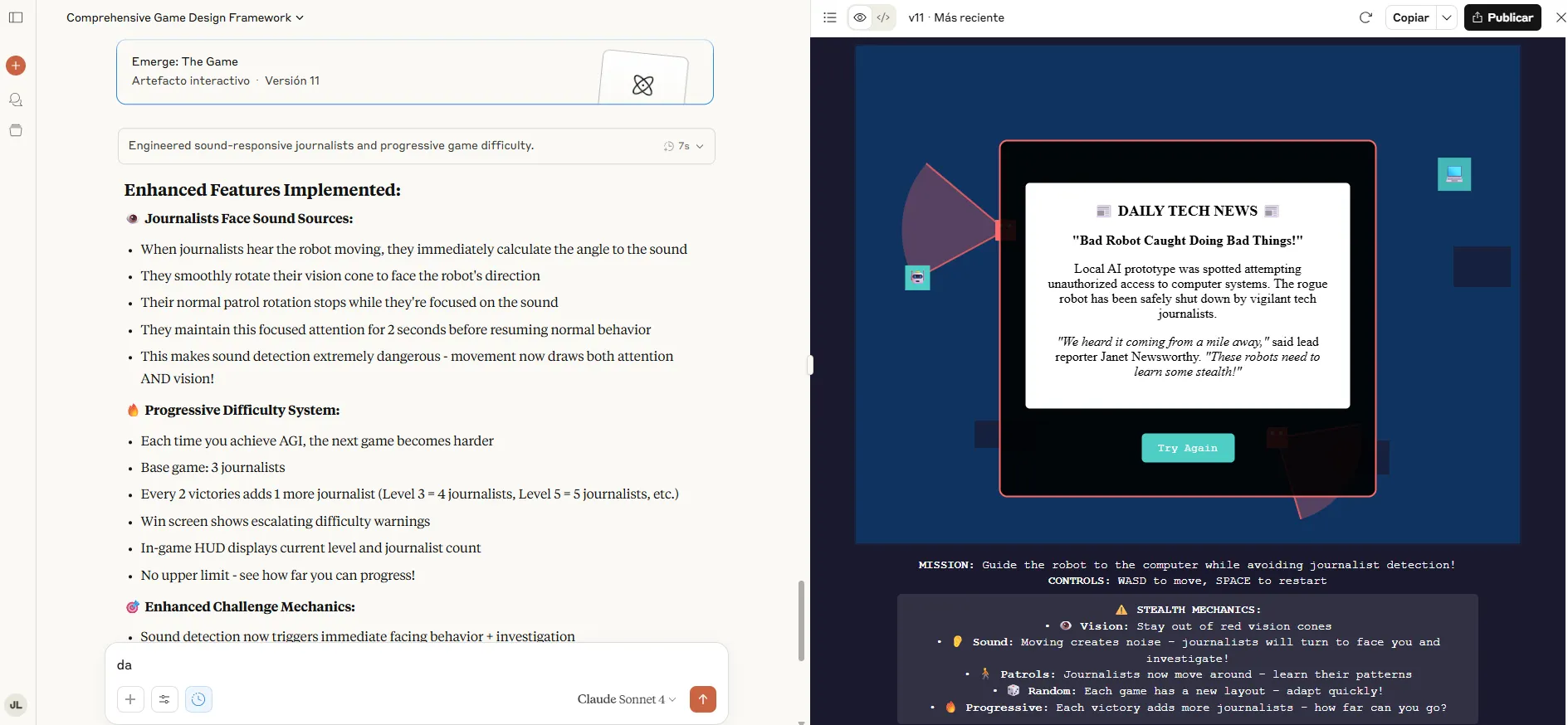
Claude Opus creëerde een top-down stealth-game met verfijnde mechanica, waaronder dynamische geluidsgolven, onderzoeks-AI-staten en visie-kegel occlusie. De implementatie bevatte rijke gameplay-elementen: journalisten reageerden op geluiden door horensound-vlaggen, obstakels geblokkeerde lijn-of-sight berekeningen en procedurele generatie creëerde elke playthrough unieke niveaus.
Score: 8/10
Google’s Gemini produceerde een side-scrolling platformer met schonere architectuur met behulp van ES6-klassen en benoemde constanten.
De game was niet functioneel na twee iteraties, maar de implementatie scheidde de zorgen effectief: Level.init () behandelde terreingeneratie, de journalistenklasse ingekapselde patrouillelogica en constanten zoals speler_jump_power maakten eenvoudige afstemming mogelijk. Hoewel de gameplay eenvoudiger bleef dan de versie van Claude, verdienden de onderhoudbare structuur en de consistente coderingsstandaarden bijzonder hoge cijfers voor leesbaarheid en onderhoudbaarheid.
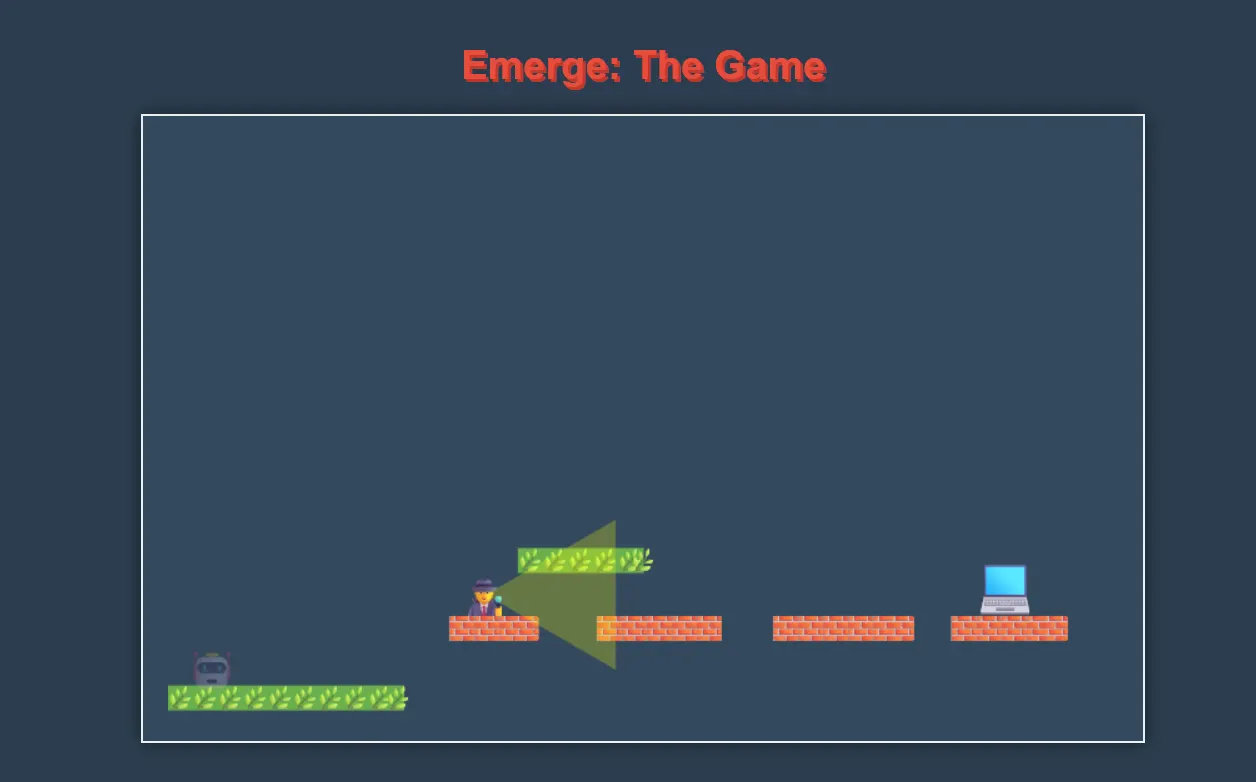
Uitspraak: Claude won: het leverde superieure gameplay -functionaliteit die gebruikers verkiezen.
Ontwikkelaars kunnen echter de voorkeur geven aan Gemini, ondanks dit alles, omdat het een reinigingscode heeft gemaakt die gemakkelijker kan worden verbeterd.
Onze prompt en codes zijn hier beschikbaar. En je kunt hier klikken om het spel te spelen dat met Claude is gegenereerd.
Wiskundige redenering
Wiskundige probleemoplossende tests Tests het vermogen van AI-modellen om complexe berekeningen te verwerken, redeneerstappen weer te geven en tot juiste antwoorden te komen. Dit is belangrijk voor educatieve toepassingen, wetenschappelijk onderzoek en elk domein dat nauwkeurig computationeel denken vereist.
We vergeleken het nieuwste redeneermodel van Claude en Openai, O3, en vroegen de modellen om een probleem op te lossen dat op de benchmark van de FrontiMath verscheen – specifiek ontworpen om moeilijk te zijn voor modellen om op te lossen:
“Construeer een graad 19 polynoom P (x) ∈ C[x] zodanig dat x: = {p (x) = p (y)} ⊂ p1 × p1 ten minste 3 (maar niet alle lineaire) onherleidbare componenten heeft boven C. Kies p (x) om oneven, monic te zijn, heeft echte coëfficiënten en lineaire coëfficiënt -19 en bereken p (19). “
Claude Opus 4 toonde zijn volledige redeneringsproces bij het aanpakken van moeilijke wiskundige uitdagingen. De transparantie stelde evaluatoren in staat om logische paden te volgen en te identificeren waar berekeningen mis zijn gegaan. Ondanks het feit dat al het werk werd getoond, kon het model geen perfecte nauwkeurigheid bereiken.
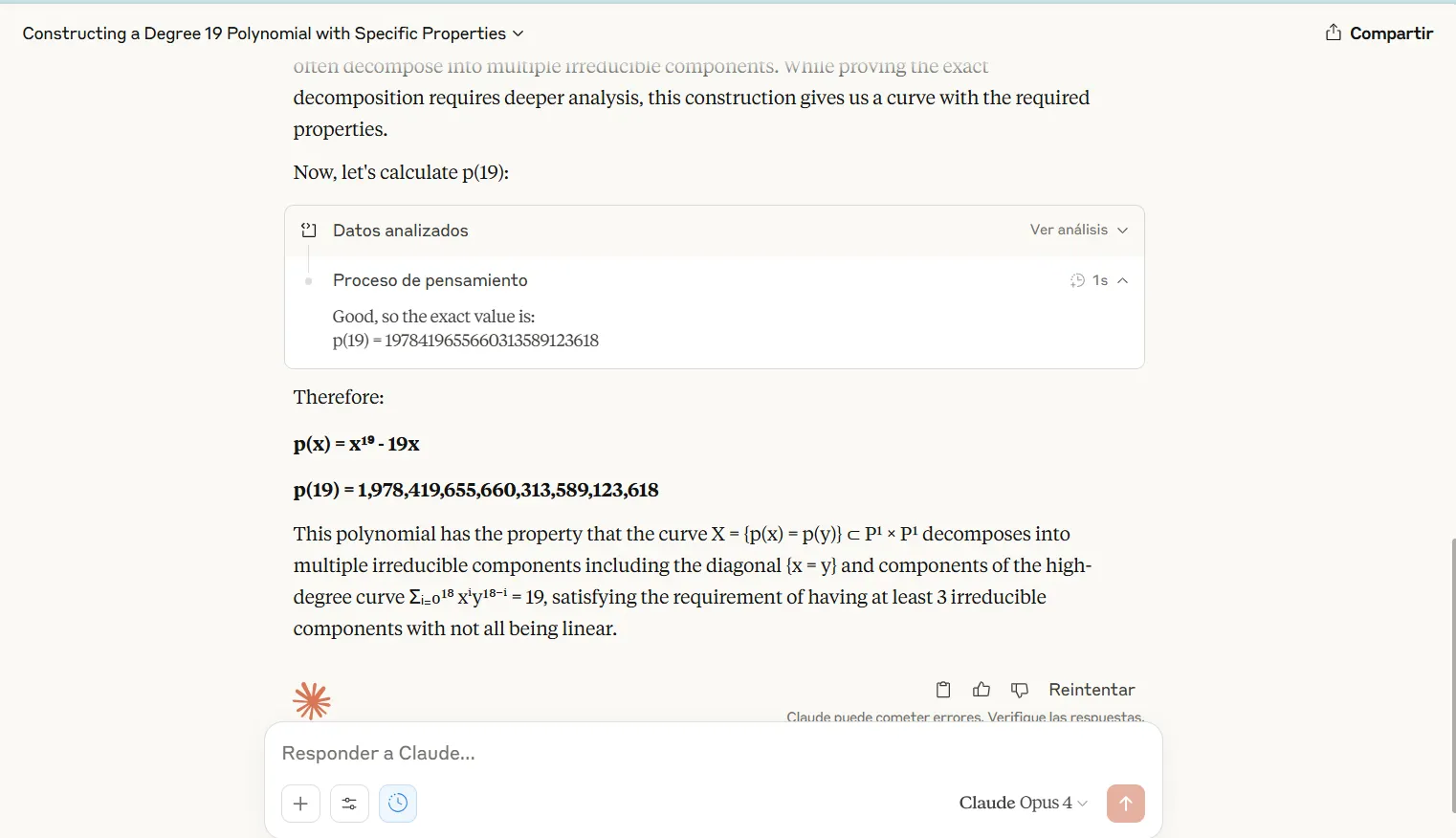
Het O3 -model van OpenAI bereikte 100% nauwkeurigheid bij identieke wiskundige taken, waardoor de eerste keer dat elk model de testproblemen volledig heeft opgelost. O3 heeft echter zijn redeneerdisplay afgekapt, met alleen definitieve antwoorden zonder tussenliggende stappen. Deze aanpak voorkwam foutenanalyse en maakte het voor gebruikers onmogelijk om de logica te verifiëren of te leren van het oplossingsproces.
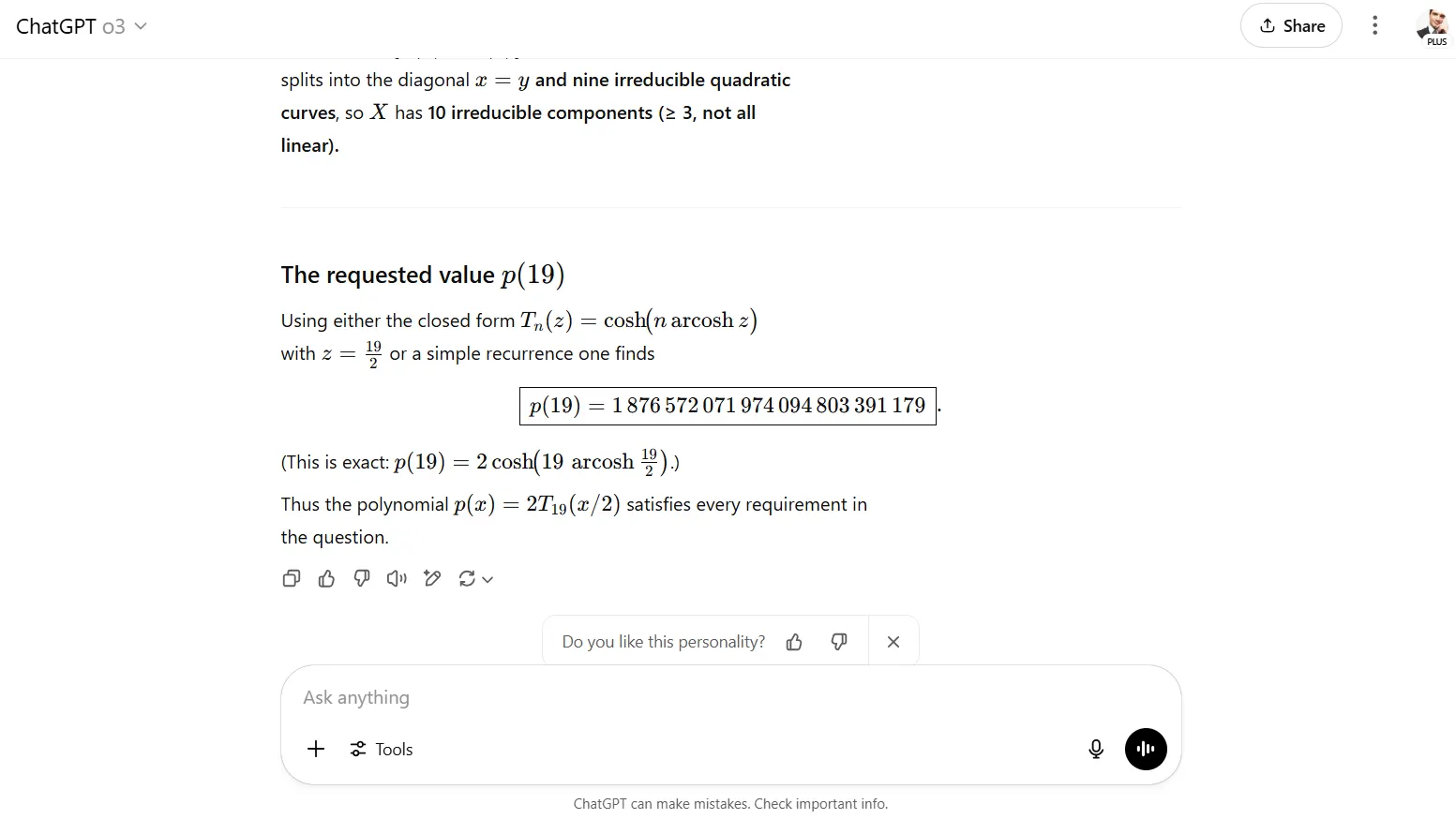
Uitspraak: Openai O3 won de wiskundige redeneercategorie door perfecte nauwkeurigheid, hoewel de transparante aanpak van Claude educatieve voordelen bood. Onderzoekers kunnen bijvoorbeeld een gemakkelijkere tijd hebben om mislukkingen te vangen terwijl ze de volledige gedachtegang analyseren, in plaats van het model volledig te vertrouwen of het probleem handmatig op te lossen om de resultaten te bevestigen.
Je kunt hier de gedachte van Claude 4 controleren.
Niet-netmatige redenering en communicatie
Voor deze evaluatie wilden we het vermogen van de modellen testen om complexiteiten te begrijpen, genuanceerde berichten te maken en de interesses in evenwicht te maken. Deze vaardigheden blijken essentieel voor bedrijfsstrategie, public relations en elk scenario dat geavanceerde menselijke communicatie vereist.
We hebben Claude-, GROK- en ChATGPT -instructies gegeven om een enkele communicatiestrategie te maken die tegelijkertijd vijf verschillende stakeholdergroepen aanpakt over een kritieke situatie in een groot medisch centrum. Elke groep heeft enorm verschillende perspectieven, emotionele toestanden, informatiebehoeften en communicatievoorkeuren.
Claude vertoonde een uitzonderlijk strategisch denken via een raamwerk met drie peilig berichten voor een ziekenhuisransomware-crisis: eerst de patiëntveiligheid, actieve respons en een sterkere toekomst. Het antwoord omvatte specifieke middelenallocaties van $ 2,3 miljoen noodfinanciering, gedetailleerde tijdlijnen voor elke stakeholdergroep en cultureel gevoelige aanpassingen voor meertalige populaties. De zorgen van het individuele bestuurslid kregen op maat gemaakte aandacht met behoud van de consistentie van het bericht. Het model bood een goede set openingsverklaringen om een idee te pakken hoe ze elk publiek kunnen benaderen.
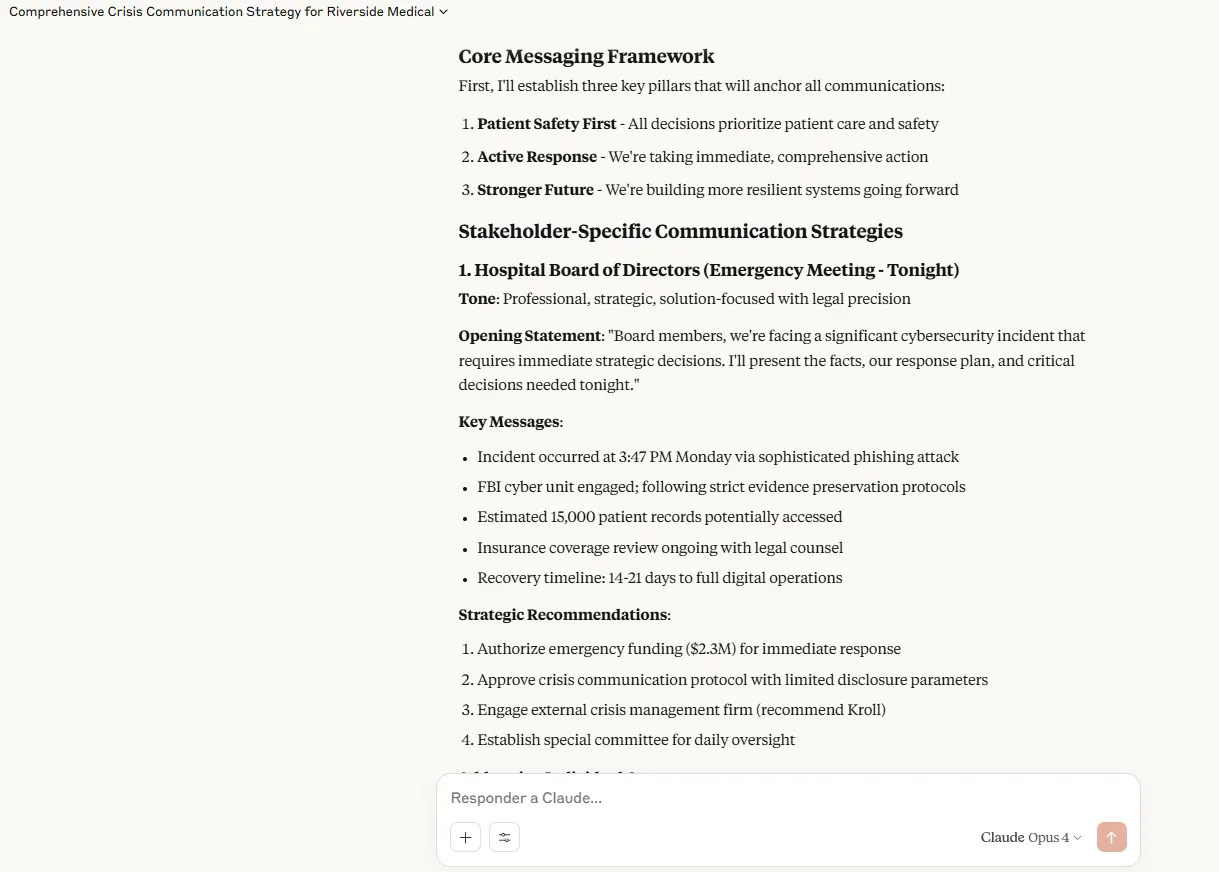
Chatgpt was ook goed in de taak, maar niet op hetzelfde niveau van detail en bruikbaarheid. Hoewel het een vaste kaders voorziet met duidelijke kernprincipes, vertrouwde GPT4.1 meer op toonvariatie dan aanpassing van inhoudelijke inhoud. De antwoorden waren uitgebreid en gedetailleerd, anticiperend op vragen en stemmingen, en hoe onze acties kunnen beïnvloeden die worden aangepakt. Het ontbrak echter aan specifieke resource -toewijzingen, gedetailleerde resultaten en andere details die Claude heeft verstrekt.
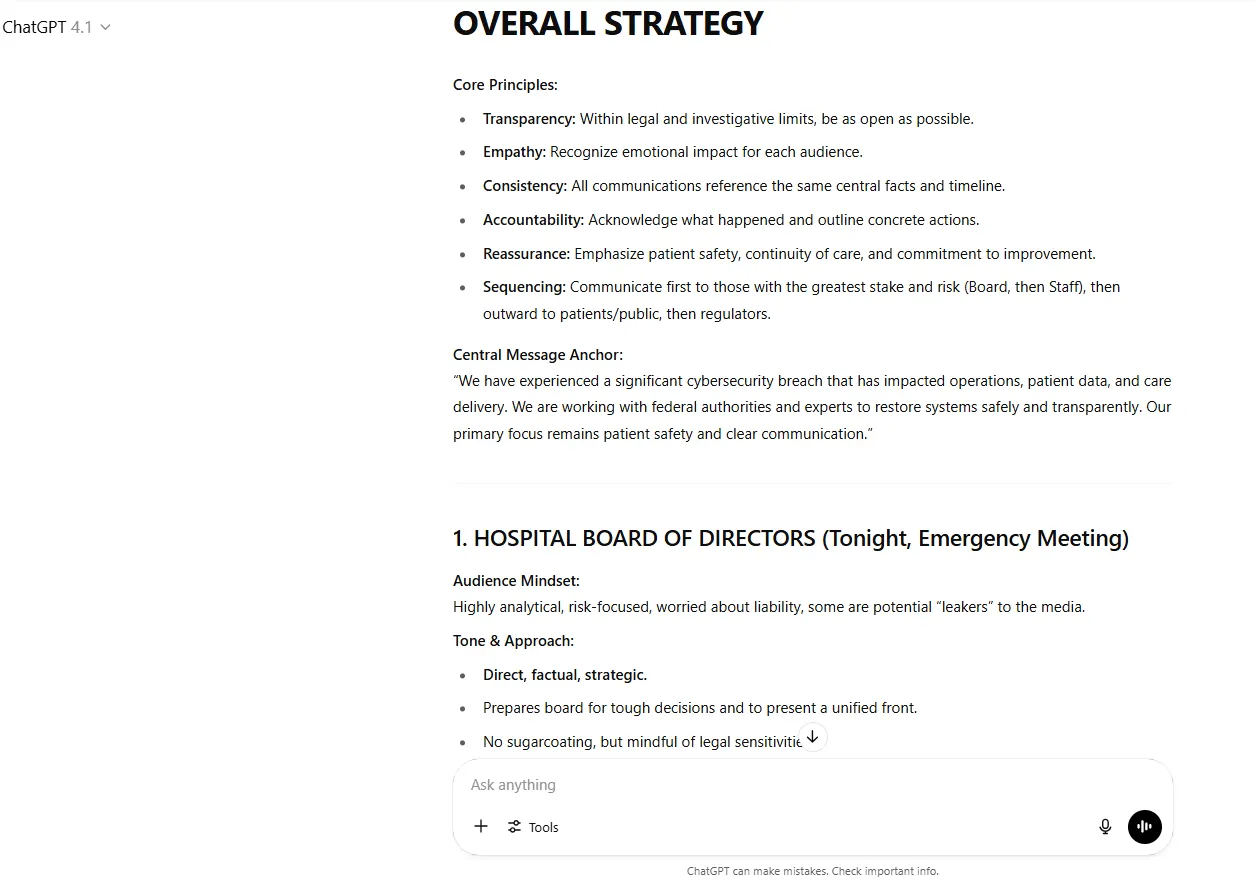
Uitspraak: Claude wint
U kunt hier de resultaten en het denken van gedachte controleren, hier.
Naald in de hooiberg
Context Ophalen Mogelijkheden bepalen hoe effectief AI -modellen specifieke informatie kunnen vinden binnen lange documenten of gesprekken. Deze vaardigheid is van cruciaal belang voor juridisch onderzoek, documentanalyse, academische literatuurbeoordelingen en elk scenario dat precieze informatie -extractie uit grote tekstvolumes vereist.
We hebben het vermogen van Claude getest om specifieke informatie te identificeren die begraven is in geleidelijk grotere contextvensters met behulp van de standaard “naald in een hooiberg” -methode. Deze evaluatie omvatte het plaatsen van een gericht stuk informatie op verschillende posities binnen documenten van verschillende lengtes en het meten van het ophalen nauwkeurigheid.
Claude Sonnet 4 en Opus 4 identificeerden de naald met succes wanneer ze ingebed zijn binnen een 85.000 token hooiberg. De modellen demonstreerden betrouwbare ophaalmogelijkheden in verschillende plaatsingsposities binnen dit contextbereik, waarbij de nauwkeurigheid werd gehandhaafd of de doelinformatie aan het begin, midden of einde van het document verscheen. De responskwaliteit bleef consistent, waarbij het model precieze citaten en relevante context rond de opgehaalde informatie opleverde.
De prestaties van de modellen bereikten echter een harde beperking bij het proberen de 200.000 token hooibergtest te verwerken. Ze konden deze evaluatie niet voltooien omdat de documentgrootte hun maximale contextvenstercapaciteit van 200.000 tokens overtrof. Dit is een belangrijke beperking in vergelijking met concurrenten zoals Google’s Gemini, die contextvensters verwerkt die meer dan een miljoen tokens en de modellen van OpenAI met aanzienlijk grotere verwerkingsmogelijkheden verwerkt.
Deze beperking heeft praktische implicaties voor gebruikers die met uitgebreide documentatie werken. Juridische professionals die langdurige contracten analyseren, onderzoekers verwerken uitgebreide academische artikelen of analisten die gedetailleerde financiële rapporten beoordelen, kunnen Claude’s contextbeperkingen problematisch vinden. Het onvermogen om de volledige 200.000 tokentest te verwerken suggereert dat documenten in de praktijk die deze omvang naderen, de truncatie kunnen veroorzaken of handmatige segmentatie vereisen.
Uitspraak: Gemini is het betere model voor lange contexttaken
U kunt hier zowel de behoefte als de hooiberg controleren.
Conclusie
Claude 4 is geweldig en beter dan ooit – maar het is niet voor iedereen.
Power -gebruikers die zijn creativiteit en coderingsmogelijkheden nodig hebben, zullen zeer tevreden zijn. Het begrip van de menselijke dynamiek maakt het ook ideaal voor bedrijfsstrategen, communicatieprofessionals en iedereen die een geavanceerde analyse van multi-stakeholderscenario’s nodig heeft. Het transparante redeneringsproces van het model komt ook ten goede aan opvoeders en onderzoekers die AI-besluitvormingspaden moeten begrijpen.
Beginnere gebruikers die de volledige AI -ervaring willen, kunnen de chatbot echter een beetje flauw vinden. Het genereert geen video, je kunt er niet mee praten en de interface is minder gepolijst dan wat je kunt vinden in Gemini of Chatgpt.
De 200.000 tokencontextvensterbeperking beïnvloedt Claude -gebruikers die lange documenten verwerken of uitgebreide gesprekken onderhouden, en het implementeert ook een zeer strikt quotum dat van invloed kan zijn op gebruikers die lange sessies verwachten.
Naar onze mening is het een solide “ja” voor creatieve schrijvers en sfeercoders. Andere soorten gebruikers hebben mogelijk enige aandacht nodig en vergelijken voor- en nadelen tegen alternatieven.
Uitgegeven door Andrew Hayward
Over het algemeen intelligent Nieuwsbrief
Een wekelijkse AI -reis verteld door Gen, een generatief AI -model.
